大模型 “准确率悬崖” 被证实,科学家发现模型单次处理容量上限,多智能体成破局关键
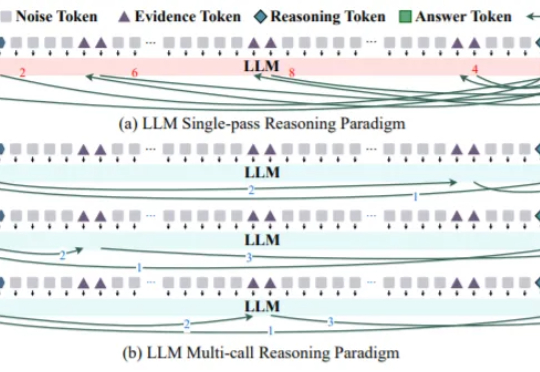
大模型 “准确率悬崖” 被证实,科学家发现模型单次处理容量上限,多智能体成破局关键近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。
来自主题: AI技术研报
9019 点击 2025-10-20 14:02
 搜索
搜索
近日,来自阿联酋穆罕默德·本·扎耶德人工智能大学 MBZUAI 和保加利亚 INSAIT 研究所的研究人员发现一个针对大模型单次推理的“法诺式准确率上限”,借此不仅揭示了单次生成范式的根本性脆弱点,也揭示了“准确率悬崖”这一现象。

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化
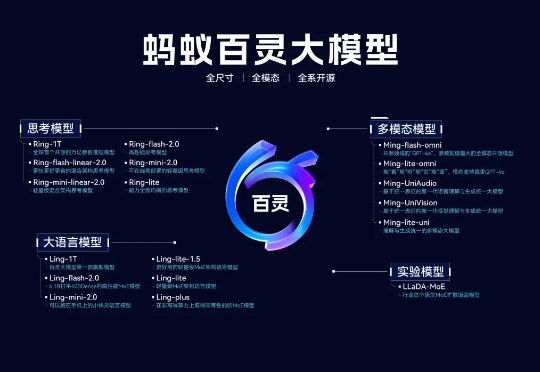
10 月 9 日凌晨,蚂蚁百灵大模型团队奇袭般官宣了一款自家最新语言大模型 Ling-1T,参数量达到 1000B(即 1万亿参数)。然而,就在十天前,百灵团队才将自研 Ring-1T-preview 大模型开源。
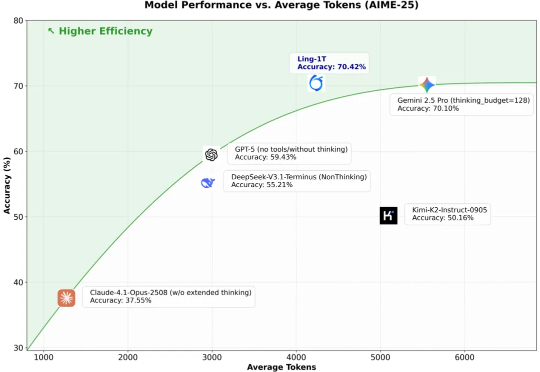
10 月 9 日凌晨,百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。至此,继月之暗面Kimi K2、阿里 Qwen3-Max 之后,又一位重量级选手迈入万亿参数LLM 「开源俱乐部」。

本周,我们邀请 3D 大模型公司 VAST 的创始人和 CEO 宋亚宸(Simon),和我们聊聊 VAST 最新 3D 生成大模型 Tripo 3.0 背后的故事。这位 97 年的创业者短期内连续融资三轮、每轮数千万美金,积攒了足够的子弹,在闷头苦干一年后,Simon 今年首次上播客,和我们探讨了几个关键的战略问题:

全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。

9 月 25 日,生数科技新一代图生视频大模型 Vidu Q2 正式全球上线,打破了原有 AI 生成的表情太假,动作飘忽不定,运动幅度不够大,无法指哪打哪的行业问题,实现从 “视频生成” 到 “演技生成”,从 “动态流畅” 到 “情感表达” 的革命性跨越,标志着 AI 视频生成技术正式从追求 “形似” 进入追求 “神似” 的新纪元
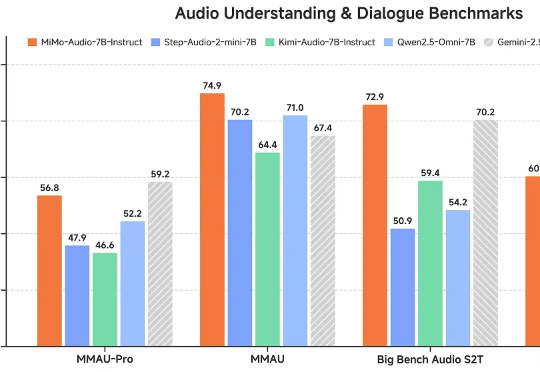
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
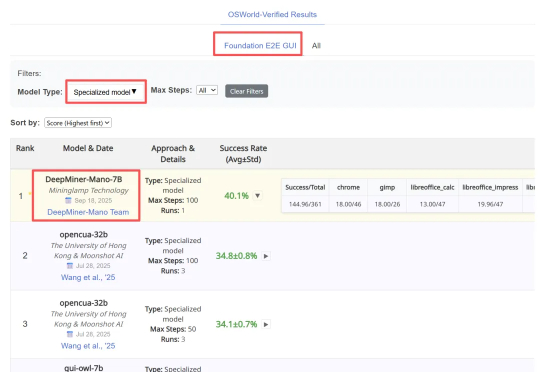
近日,明略科技推出的基于多模态基础模型的网页 GUI 智能体 Mano,凭借其强大的性能,在行业内公认的两大挑战基准 ——Mind2Web 和 OSWorld 上同时刷新纪录,取得当前最佳成绩(SOTA)。
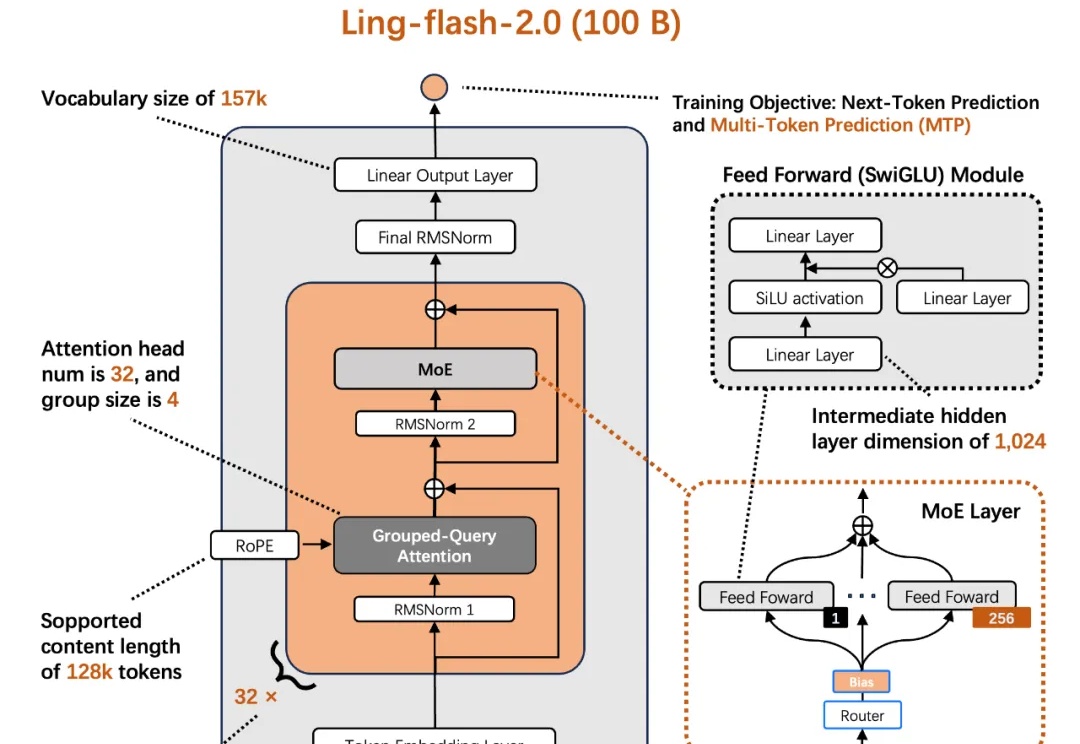
今天,蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。